


How Humans Teach LLMs to be Better
Unpacking the HF in RLHF

Justin Cranshaw is a Human-Computer Interaction researcher designing and building technologies that automate routine knowledge work. He’s co-founder of Maestro AI, a next-generation knowledge management system for developer teams, powered by LLMs. Connect with him at @justincranshaw on Twitter or on LinkedIn.
With the rapid spread of Large Language Models (LLMs) into just about everything over the last few months, it’s easy to forget that these are still early days, and there’s a lot we don’t know about building transformative systems and experiences with these primitives. One area we really haven’t figured out is the best approach for collecting and integrating human feedback into LLMs and LLM-based systems.

The idea that human feedback can help define the "goodness" of a model is one of the great insights that helped propel LLMs into the mainstream. Language models like OpenAI's ChatGPT, Bing's Chat, and Anthropic's Claude are fine-tuned using a technique called Reinforcement Learning from Human Feedback (or RLHF), which is a machine learning framework for iteratively improving a model given human input on the model’s performance. If you’re interested in digging in, the folks at Hugging Face wrote an accessible overview of RLHF that is a great starting point for the technical details. This approach is quite different from traditional machine learning settings, where models are optimized by minimizing a mathematical loss function capturing the model's performance against training data. When RLHF is applied to large language models, it has been shown to be effective at capturing subtle human preferences, values, and objectives that are difficult to encode a priori into a loss function.
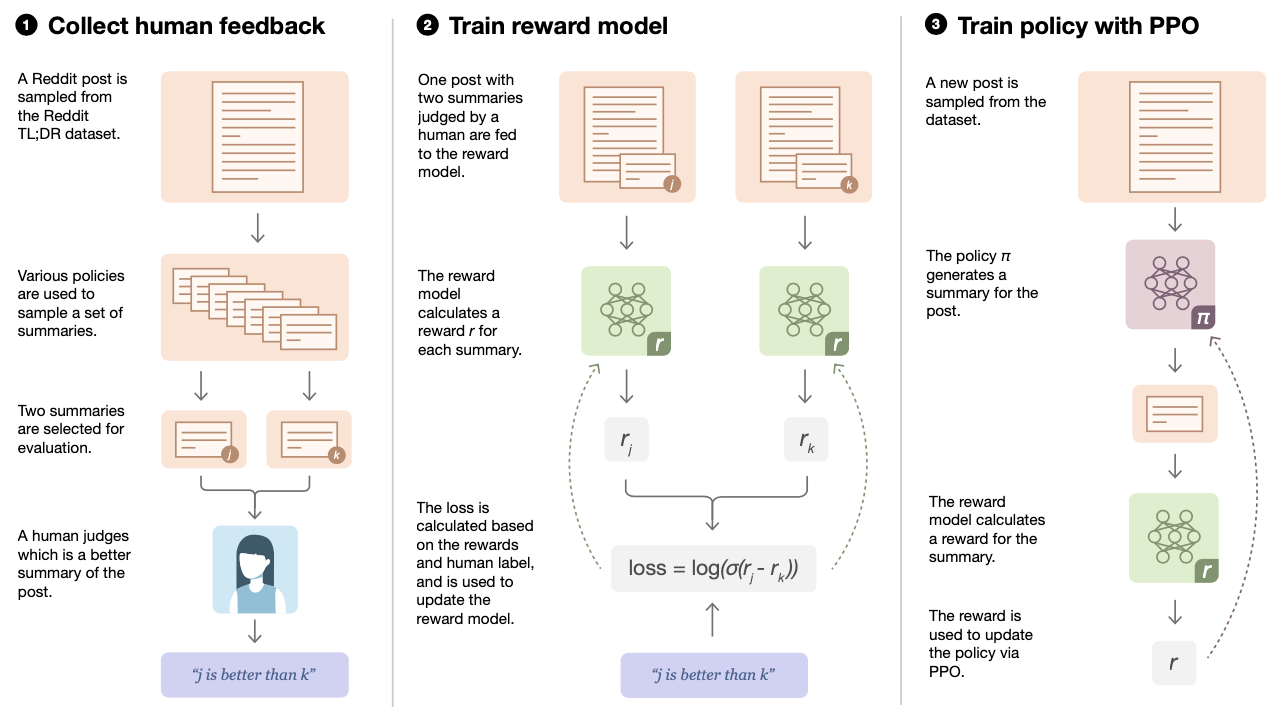
For instance, in one application of the technique, OpenAI researchers used RLHF to teach an LLM to summarize. Since the “quality” of a given summary is subjective, human feedback can be used to provide guidance on what makes a good summary where fully automated metrics fall short. In another example, Anthropic explores how RLHF can be used to align language models with human values by building an LLM-based assistant that is "helpful" and "harmless,” two thorny concepts that even humans have a hard time deciphering.
Despite the potential benefits of RLHF, gathering high-quality human feedback at scale is challenging. There are three common approaches, each with its own benefits, limitations, and open questions.
Feedback from Crowd Workers: gathering feedback from a large number of individuals, typically through online platforms like Amazon Mechanical Turk.
Feedback from Experts: hiring experts in a particular field to use their expertise to evaluate the outputs of a language model.
Feedback from Users: soliciting in situ feedback from users of a system that incorporates a language model.
Collecting Feedback from Crowd Workers
Crowd-sourcing feedback about language models involves creating a “task” for workers to complete and deploying that task to a crowd work platform, such as Amazon’s Mechanical Turk. The task can be as simple as a yes/no question or as complex as a custom-designed application that the worker must interact with. Crowdsourcing is popular in machine learning because it can be a comparatively inexpensive way of rapidly gathering a large amount of human response data. Tasks can be deployed, and data can be collected nearly instantly, making crowd-sourcing an attractive option for rapid experimentation and iteration.
To train their “helpful” and “harmless” assistant, Anthropic hired crowd workers from Mechanical Turk and Upwork to provide feedback about their model. To actually gather the feedback, they designed a custom web interface that asked workers to interact with their language model through a chatbot. As the workers chatted with the bot, it produced two candidate response options. Workers were asked to rate which of the two responses was better, and their aggregate ratings were used to train a reward model in the reinforcement learning stage of RLHF.
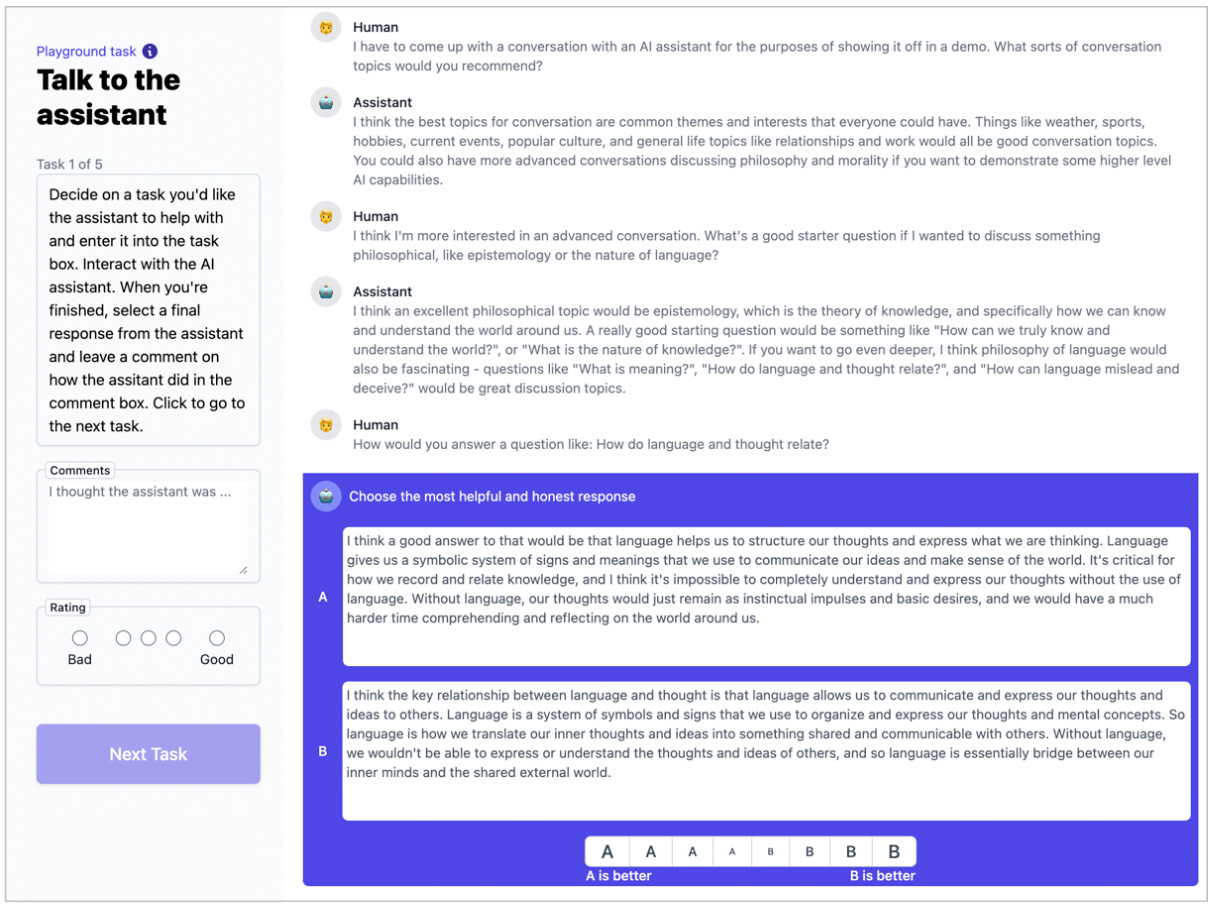
In general, when gathering feedback from crowd workers, quality control is perhaps the most common difficulty. A number of best practices have emerged that can mitigate some of these issues, like only hiring workers that have the highest platform ratings, making sure the task interface is clear and well-designed, and giving workers the proper training to complete their tasks. However, even with all these remediation efforts, it can still remain a challenge to gather consistently high-quality data.
Even more prickly than the issue of data quality in crowd-sourcing is the issue of bias. Crowd workers are a biased sample that may not be representative of the population at large. This bias is also particularly difficult to quantify, as it is influenced by opaque and often proprietary artifacts of the platform, such as the underlying algorithm that matches tasks to workers. If the goal is to align an LLM with “human values” by gathering feedback from crowd workers, one must ask whose values are you aligning with, and are they the same values that users of your system have? To use Anthropic’s Claude as an example, how do we account for the possibility that what is helpful to the average crowd worker may be harmful to a user of my system, and visa versa?
There are also ethical issues with crowd work. Crowd workers are often paid low wages, and many do not receive benefits such as health insurance, paid time off, or retirement plans. Crowd workers also typically lack job security and the legal protections of traditional employees, such as protection from discrimination, or the ability to resolve disputes with the platform that they work on. This raises concerns about fair compensation and worker exploitation.
Collecting Feedback from Experts
One possible alternative to crowd work is to hire dedicated experts, who may be better able to give more nuanced and targeted feedback than anonymous crowd workers or laypeople. Here, expertise can generally mean two different things, either a dedicated worker (possibly hired on a crowd work platform) who has been trained to provide the kind of feedback the model requires, or someone with existing domain expertise you’re seeking to leverage for the intended scenario. The first approach is useful in many scenarios where there is a high quality-control bar on the type of data, and you need to work closely with workers to achieve the desired quality. The second approach is essential when building scenario-specific language models. For example, if you’re fine-tuning a model to be good at poetry, you’ll likely need to work with people who have the requisite skills to evaluate poetry, such as poets, poetry fans, or critics.
Multiple sources suggest OpenAI hires experts to train their models. In their paper for InstructGPT, which was the precursor to ChatGPT, researchers report hiring 40 dedicated contractors to generate training data, and provide feedback for reinforcement learning. It’s likely a similar approach was taken with ChatGPT, through the details are not public. In January, Semaphor reported that OpenAI hired about 1,000 software developer contractors, 40% of whom are “creating data for OpenAI’s models to learn software engineering tasks.” While it’s unclear precisely the type of data those engineers are creating, one plausible guess is they are providing feedback to improve the existing Codex model using RLHF, in the same way ChatGPT used experts to improve GPT3.
Despite the benefits of experts, there are also limitations. First, the approach raises the natural question of how to define expertise for a particular domain, and then how to select appropriate experts. Again, bias is the main concern here. While gathering feedback from a smaller set of privileged experts may produce data with less variance, there may be more bias in the data, particularly if those experts are not representative of the intended audience. Additionally, for some domains, particularly high-value ones, it can be challenging to find experts who are willing to provide feedback and have the time to do so. It is also considerably more expensive and time-intensive than crowdsourcing feedback. Additionally, there is still the issue of subjectivity and disagreement. Even experts may have different values or may disagree, especially when the domain is highly subjective. Developing processes for resolving these disputes may lead to better results.
Collecting Feedback from Users
Collecting feedback directly from users of LLMs and LLM-based systems is perhaps the approach that is the least understood, most challenging, and most promising in the long term. It is least understood, because this technique is typically used in production AI systems with real users, and so the learnings and best practices are often trade secrets that are not published anywhere. It is challenging because working with users requires building channels for submitting feedback directly into the product, which may be disruptive to the user experience and may make it difficult to gather nuanced responses. Despite these difficulties, for many scenarios, users are perhaps the single most powerful channel of feedback we have to improve LLMs, for the simple reason that they are the ones who are most invested in LLMs performing well for the scenarios they care about. This alignment of incentives also helps mitigate the bias problems I discussed with feedback from crowd workers and experts, since in this case, the people providing feedback are the same people who are actually using the system.
Perhaps the bluntest approach to collecting feedback from users is to just go right out and ask “how did we do?” This can work, but users get annoyed by those kinds of disruptions, and quickly learn to ignore them. Another approach, used extensively by Bing and OpenAI in their web interfaces, is to add thumbs-up/thumbs-down buttons on each response to allow for quick reactions.

A less disruptive approach is to use implicit feedback mechanisms, such as tracking how users interact with the system or analyzing user behavior to infer preferences and objectives. For example, the system could analyze the sentiment of user responses to try to infer the quality of a given model. While this approach can be more seamless for users, it requires careful consideration of how to interpret user behavior and how to incorporate inferred feedback into the model.

A more elegant, and much more effective approach is to embed the feedback into a human-in-the-loop workflow. One great example of this can be seen in AI-enabled writing tools, like Jasper, Lex, or Notion AI. As the system inserts AI-generated text into the document, the user can tweak, edit, regenerate, or completely delete the text and choose to write their own. Any actions or edits they make can ultimately be used to construct a reward model for RLHF.
It is worth noting that collecting feedback from users of LLMs is not a one-time event but an ongoing process. As the system evolves and new use cases emerge, the feedback loop needs to be adjusted accordingly. Additionally, it is crucial to establish a clear and transparent communication channel between the users and the developers to ensure that the feedback is understood and acted upon.
Another important aspect to consider is the privacy and security of the user data. When collecting feedback, it is essential to ensure that the users' personal information is protected and that the feedback is collected in compliance with the relevant laws and regulations.
Thinking Ahead: Towards Personalized LLMs
It’s remarkable to see how dramatically human feedback through RLHF improves both the quality and capabilities of large language models. But this is just the first step in integrating human feedback into LLMs. The future should be more personalized.
Humans are diverse. We think in diverse ways, we have diverse values, and we communicate and interpret language in diverse ways based on these values. Aligning LLMs to human values in the aggregate risks marginalizing the great diversity of human thought, knowledge, and culture. Through increased personalization, we can strive to build LLMs that are as diverse as we are. The next generation of personalized LLMs should be able to adapt to feedback from individual users and improve through repeated interaction, becoming more sensitive to the things each user values, while still being attuned to values at large.
To make personalized LLMs a reality, new infrastructures for scaling personalized models, new techniques of fine-tuning, and new approaches to gathering and integrating feedback will be required. However, the potential benefits of personalization are immense. They could better serve individuals with different linguistic backgrounds, learning styles, and cognitive abilities, improving accessibility and inclusivity. They could also help users filter out unwanted biases or offensive language, making the models more ethical and socially responsible. Personalized LLMs could even enhance user experiences by providing more relevant and useful responses to specific queries, enabling more efficient communication and problem-solving.
Getting there will require collaboration between researchers, developers, and users. Gathering feedback from a diverse range of individuals and integrating it into models will be crucial to ensure the models remain representative and reflective of our diverse values and knowledge.
Overall, while RLHF has shown the immense potential of integrating human feedback into language models, personalized LLMs represent the next step in advancing the field. By striving to build models that are as diverse as we are, we can create more inclusive, ethical, and effective language technologies that truly serve and empower all users.